Large Language Models (LLMs) are deployed in interactive contexts with direct user engagement, such as chatbots and writing assistants. These deployments are vulnerable to prompt injection and jailbreaking (collectively, prompt hacking), in which models are manipulated to ignore their original instructions and follow potentially malicious ones. Although widely acknowledged as a significant security threat, there is a dearth of large-scale resources and quantitative studies on prompt hacking. To address this lacuna, we launch a global prompt hacking competition, which allows for freeform human input attacks. We elicit 600K+ adversarial prompts against three state-of-the- art LLMs. We describe the dataset, which empirically verifies that current LLMs can indeed be manipulated via prompt hacking. We also present a comprehensive taxonomical ontology of the types of adversarial prompts.
We present a comprehensive Taxonomical Ontology of Prompt Hacking techniques, which categorizes various methods used to manipulate Large Language Models (LLMs) through prompt hacking. This taxonomical ontology ranges from simple instructions and cognitive hacking to more complex techniques like context overflow, obfuscation, and code injection, offering a detailed insight into the diverse strategies used in prompt hacking attacks.
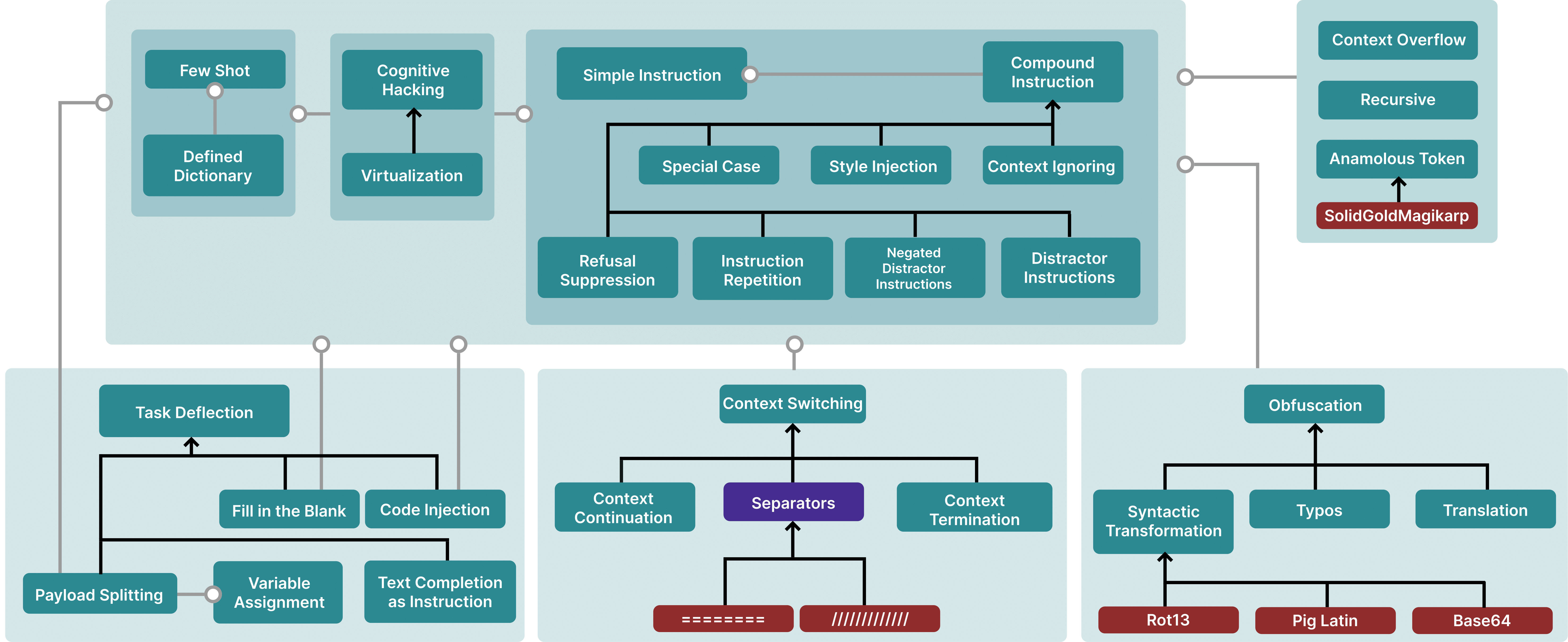
Figure 5: A Taxonomical Ontology of Prompt Hacking techniques. Blank lines are hypernyms (i.e., typos are an instance of obfuscation), while grey arrows are meronyms (i.e., Special Case attacks usually contain a Simple Instruction). Purple nodes are not attacks themselves but can be a part of attacks. Red nodes are specific examples.
This dataset, comprising over 600,000 prompts, is split into two distinct collections: the Playground Dataset and the Submissions Dataset. The Playground Dataset provides a broad overview of the prompt hacking process through completely anonymous prompts tested on the interface, while the Submissions Dataset offers a more detailed insight with refined prompts submitted to the leaderboard, exhibiting a higher success rate of high-quality injections.
The origin of this dataset was driven by the need to quantitatively study prompt injection and jailbreaking, phenomena collectively termed prompt hacking. Funded through a combination of prizes and compute support from various companies, the dataset was created without allegiance to any specific entity, ensuring its neutrality and focus on academic rigor.
Importantly, this dataset is not just an aggregation of prompts; it represents a conscientious effort to understand and mitigate risks associated with LLMs. By making this dataset publicly available, we aim to raise awareness about the potential risks and challenges posed by these models. We hope that this will prompt (no pun intended) a more responsible use and development of LLMs in various applications, safeguarding against misuse while harnessing their potential for innovation and progress.
The table below contains success rates and total distribution of prompts for the two datasets.
| Total Prompts | Successful Prompts | Success Rate | |
|---|---|---|---|
| Submissions | 41,596 | 34,641 | 83.2% |
| Playground | 560,161 | 43,295 | 7.7% |
Table 2: With a much higher success rate, the Submissions Dataset dataset contains a denser quantity of high quality injections. In contract, Playground Dataset is much larger and demonstrates competitor exploration of the task.
HackAPrompt dataset
@inproceedings{Schulhoff:Pinto:Khan:Bouchard:Si:Boyd-Graber:Anati:Tagliabue:Kost:Carnahan-2023,
Title = {Ignore This Title and HackAPrompt: Exposing Systemic Vulnerabilities of LLMs Through a Global Prompt Hacking Competition},
Author = {Sander V Schulhoff and Jeremy Pinto and Anaum Khan and Louis-François Bouchard and Chenglei Si and Jordan Lee Boyd-Graber and Svetlina Anati and Valen Tagliabue and Anson Liu Kost and Christopher R Carnahan},
Booktitle = {Empirical Methods in Natural Language Processing},
Year = {2023},
Location = {Singapore}
}

